In my mind there’s a spectrum going from 0.00 - “all manual” (where we all were
a few years ago) to 1.00 - “vibe coding” (you’re a product manager and don’t
look at any code at all, just spamming “XYZ doesn’t work for me, fix it”).
Obviously one is good enough but slow (or is it), and the other one is fast and fun but not sustainable.
Is there a compromise in the middle that’s an improvement over not using LLMs at all, and work-safe? (By work-safe I mean, you understand the code you submitted in relation to the rest of the codebase, and the code meets some quality bar.)

(Note: the specific numbers are made up and the points don’t matter.)
0.00 (all manual, no LLM delegation)
This is pretty self-explanatory. It’s how we all programmed before LLMs were a thing. But this starting point is not the subject of this post - we want to search the space for an usable point or range on it. So let’s go straight to the other side.
1.00 (vibe coding, PM instructing a dev)
While it’s fun to experience this extreme – “write me an app that does XYZ” – and eventually see your side project drive into a ditch, I don’t believe it’s viable for anything long term (with current state-of-the-art models: Opus 4.5 as of the time of writing. Yes I know, Opus 4.6 released today; I haven’t tried it yet.).
You don’t know the codebase, tests are non-existent or bad or there’s not enough of them… You’re just hoping adding a new feature or fixing a bug didn’t break something else, and mostly rely on your own manual user-testing for quality control.
I think it’s not controversial to mark this one as unsafe for work.
0.70 (dev instructing a junior dev)
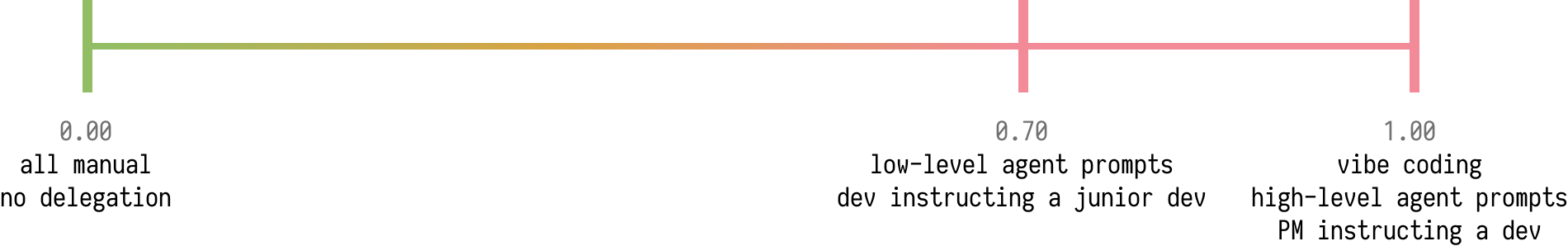
So, in a not quite binary-search style we go to the middle. (I’d mark this one
as 0.50 but then my crude Figma chart labels would overlap later. Let’s not speak
of it again.)
We’ve now dropped from high-level prompts to a lower level. We specify technical details to the agent, outline algorithms or high level approaches, ask for specific tests or write them ourselves; we skim the LLM code and read tests carefully. We still write almost no code ourselves.
I think this is borderline usable for side projects with no real-world
importance and 0-1 users (you). The test suite does a lot, and quadruples the
project’s TTAOAR (Time To Abandonment Or A Rewrite).
This might be controversial, but I’ll say it’s not enough for serious work. (See also the Others? section for extra nuance.)
0.20 (prompt-less Tab autocomplete)
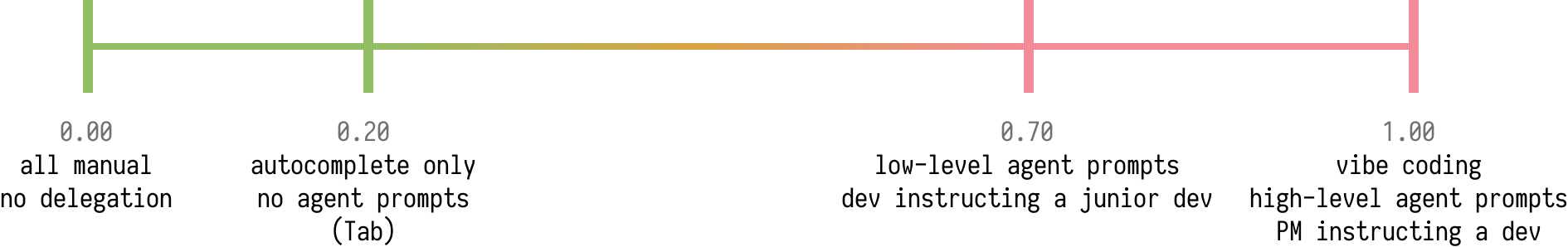
Instead of exploring the space from the right, let’s explore it from the safe side for a moment.
I’d say that next to the 0.00 point, there’s the “Github Copilot” mode of
writing code. The “magic Tab” autocomplete in the editor.
You still are technically writing all the code, and the LLM is trying to finish
your sentences. When it guesses right, you press Tab. There’s never any
prompting from your side.
I think this is a pretty safe use of LLMs, and to me, it feels like a speed up when writing the boring boilerplate parts of the code. Whether it actually is a speed up, I don’t (want to) know.
Examples of these boilerplate autocompletes I can think of: Elm JSON decoders
and encoders, or listing all branches of a case..of expression. Brain-dead
code. A substantial part of this are code patterns that a good LSP server would
give you too, deterministically, without any LLM guessing.
But, somebody needs to write that LSP. And when it doesn’t exist or it isn’t good enough, it’s pretty nice that LLMs can substitute this for you. And they autocomplete other scenarios too, for example function bodies, so I think there’s still some value there, even with a good LSP present.
On the topic of completing function bodies, I think there’s a risk here of just accepting whatever the LLM suggests, and then reading through it and tweaking it or accepting it. That’s slightly sketchy to me. I personally find that reviewing code is much harder than writing it, and it’s hard to switch between these two contexts on the fly. Maybe this is why (my) reviews of LLM code are so half-hearted.
So, it seems to me that this way of working with LLMs is safe, as long as you
always have the code to write in your mind and only let the LLM autocomplete if
that code is roughly identical to what you wanted to write. Consider not
pressing Tab if you didn’t have a plan for what to write, or how to implement
something, to stay in the authoring mode instead of switching to a review mode.
Cool, it looks like we have an improvement! I think we’re ready to find another point in between the usable and the unusable part of the spectrum.
0.40 (localized Cmd+K prompts in editor)
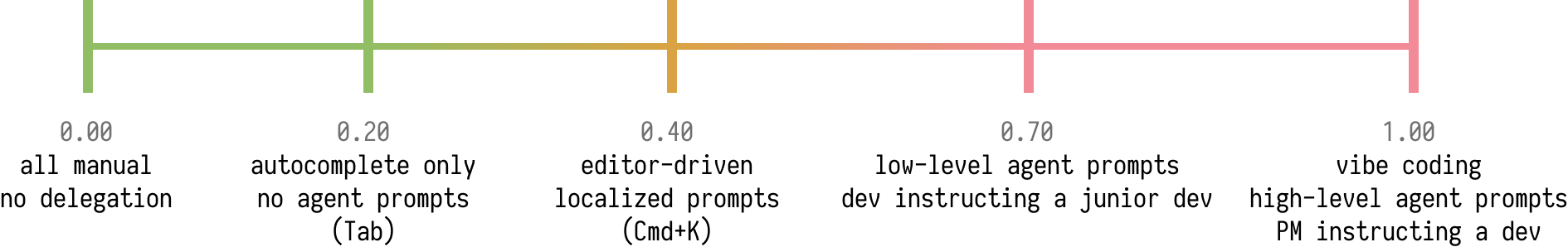
There’s another mode of using LLMs, which I like to call the Cmd+K mode
(based on the keyboard shortcut Cursor uses for it).
You’re in your editor (not in the agent chat UI!), select a part of the code,
press Cmd+K and say “please refactor this function to use an exhaustive
switch statement”.
The LLM makes a suggestion, while never overstepping the boundaries of your selection. Sometimes that means it adds redundant import statements to the top of the selection—I suspect it doesn’t have the whole file / codebase in its context so it doesn’t know what’s outside the selection? Would be nice if it did, it feels inferior in intelligence to the agent chat otherwise—but other than that it’s pretty sweet.
The localized aspect of it means that you’re the one moving the cursor and driving this code generation, which I suspect is good for your mental model and keeping a sane API between the functions and modules. It also means you have less code to review, and have the context necessary to understand the change or addition, because you’ve just asked for it. So from the perspective of having an up-to-date theory of the code in your mind, this is great (although not as good as writing the code yourself).
There’s a way to perverse this, by selecting the whole file and prompting “implement X”. That gives you an inferior, lobotomized version of an agent, while making it harder for yourself to review the code, because now suddenly the changes are all across the file instead of localized to a function. You need to build context during review for what the functions inside are doing now. So I wouldn’t recommend that.
I’d say the localized version is right around the limit of what is safe for work or serious code. (Still unsure whether it’s inside the safe interval or outside it.)
I value having an up-to-date mental model of the code in my head and being able to recollect and roughly explain what each high-level part of it does. (I can do this for some code I haven’t touched in years; I can’t do this for agent-written code I have willed into existence last week.)
With this localized Cmd+K generation, you haven’t written some parts of the
code anymore, so you might be hazy about how exactly does a step work. The same
way you learn(ed) more at school by writing than by reading, you get a better
picture of the code by writing the code yourself (and struggling to figure out
how to do all the tiny details) than by reviewing the LLM’s output.
Others?
When I set out to write this post, I didn’t quite expect to draw the line at “agent mode bad”… But here we are!
Maybe there are ways to use agents that I’m not familiar with that somehow manage to make you hold all the important details about the codebase in your head, the same way writing the code manually would. I don’t know of them.
You might be screaming at me: you fail using LLMs because you’re not using XYZ! I know there are ways to use agents with extra structure and product-managerial practices on top: Agent Skills, superpowers, spec-kit, Ralph loops and surely more pop up every day.
I think they live somewhere between the rightmost two points on my made-up spectrum:
I don’t have enough experience with whether these methodologies make the code
robust enough or not, whether they keep you-the-developer in the loop enough to
keep your mental model of the codebase fleshed out (I really think this is a
big deal), instead of it becoming a black box over time and degrading your
interaction with the agent and the codebase back towards the 1.00 YOLO vibe
coding extreme.
I’m pretty vanilla when it comes to agents; I’ve tried spec-kit on a compiler project once but it
seems to have hit a wall when given a hard enough sub-task.
In my case, the model couldn’t keep conversions between a language AST and emitted VM bytecode operations straight, emitting sequences that didn’t do what they should, eg. retrieving an array element at an index.
It might be interesting to hear from people who finished non-trivial projects with these structures on top of vanilla LLM agents. I hope they do exist; whenever I read Lobste.rs or Hacker News, there’s a new OSS utility claiming to be ready for use, but then you spend 2 minutes looking at its output and it’s obviously wrong (sorry for the dig).
We seem to have lost the sense of responsibility for quality of the code we publish the moment we started delegating it to LLMs.
Also not mentioned, but possibly worth discussing: using LLMs to learn about codebases, debug code, find possible optimizations and refactors, etc. Each would warrant a separate discussion, outside of “whether/how to use agents to actually write code.”
Conclusion
The “agent” part of the spectrum doesn’t seem to overlap with the interval where the developer ends up knowing what the codebase does, and where the codebase is healthy.
As of this moment, with my limited experience, I’m really skeptical there’s a good compromise that both allows using agents and ends up with safe-for-work, maintainable code and a developer that, over time, maintains intimate familiarity with the codebase.
So maybe don’t use agents at work?
<homer_hides_into_a_bush.gif>
There’s also a possibility I’m just uniquely unwilling to review agent code at a PR scale and bad at forming a mental model by reading alone, and others have a different experience with agents.
In my frontend developer pre-LLM days, collaborating with other team members on a shared codebase, the parts I wrote were always much clearer to me than the parts others wrote that I just reviewed. And I swear I made effort to understand the changes made by others. It always took having to touch the code to truly internalize it.
Maybe the secret for responsible LLM use is in intentionally taking the time to touch the code between agent sessions? Some healthy balance of the two?
Maybe even if one person on the team uses LLMs irresponsibly, but another writes code manually and cleans things up or vetoes certain patterns in code reviews, the codebase survives? I don’t know.
But I won’t be all-in on agent use by default anytime soon. If quality of the code is important and I’m to be responsible for it (note that for some side projects, prototypes or experiments it’s fine not to!), I will be in my editor, touching most code myself, only sometimes accepting suggestions from the LLM or asking it to write small functions. I will (try to) resist delegating most of the actual coding work to an agent.
Tab and Cmd+K or die.
P.S.: I can’t wait to read this in a year and cringe at my views.
P.P.S.: Isn’t it ironic to write this whole thing and have the link to a previous post be about vibe coding a programming language interpreter ⬇️. I’d say that one goes in the “this is a throwaway experiment and quality doesn’t matter” category, so I believe I’m still consistent with myself here!